

MRC distributes data packets simultaneously across hundreds of paths instead of a single one, virtually eliminating network bottlenecks. When individual connections fail, the protocol reroutes traffic in microseconds — a process that previously took seconds.
This allows training runs to continue even when hardware faults occur, without GPUs sitting idle. And instead of three or four layers of network switches, MRC needs only two to connect more than 100,000 GPUs — saving both power and cost.
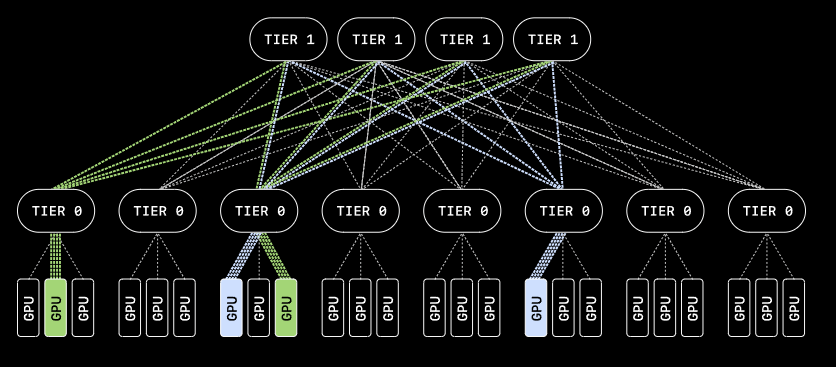
MRC distributes packets concurrently across many paths, preventing the bottlenecks that would otherwise slow down synchronous AI training.
The protocol is already deployed in OpenAI's largest NVIDIA GB200 supercomputers, including the Stargate site in Abilene as well as Microsoft's Fairwater supercomputers. During the training of a recent model for ChatGPT and Codex, four switches had to be restarted — and thanks to MRC, this happened without any coordination with the training team.
The MRC specification was published today via the Open Compute Project (OCP), along with a companion research paper. The development effort involved AMD, Broadcom, Intel, Microsoft, and Nvidia alongside OpenAI.
MRC represents a fundamental shift in AI supercomputer networking — by routing data across hundreds of parallel paths and recovering from hardware faults in microseconds rather than seconds, it directly eliminates the GPU idle time that has long been one of the hidden costs of large-scale AI training. With the protocol already proven in production at OpenAI's Stargate and Microsoft's Fairwater clusters, and its specification now open via OCP with backing from every major chip vendor, MRC has every chance of becoming the industry standard for next-generation AI infrastructure.

 ES
ES  EN
EN